Azure Natural Language API is one of Microsoft Cognitive Services API which provides a wide range functionalities from text analytics, Q&A, to text translation and chatbot. This article introduces the sentiment analysis capabilities of text analytics API. In order to call API services from Azure Portal, it requires a valid subscription, an endpoint request, request parameters, JSON-structured data and finally explore JSON responses of API.
1) Subscription
In order to create a resources on Portal Azure, the very first step is to have a Microsoft account and a valid subscription. Microsoft offers you an free Azure account with 200 credits to explore Azure Services in 30 days. Check out the Part 1 to see creation steps.
2) Endpoint Request
Endpoint is where we send the request and process it. It consists of URI and non-expired subscription key and . When we succeed in creating an account and a subscription on Portal Azure, we continue adding a new resource for text analytics:
Click on "Create a resource"
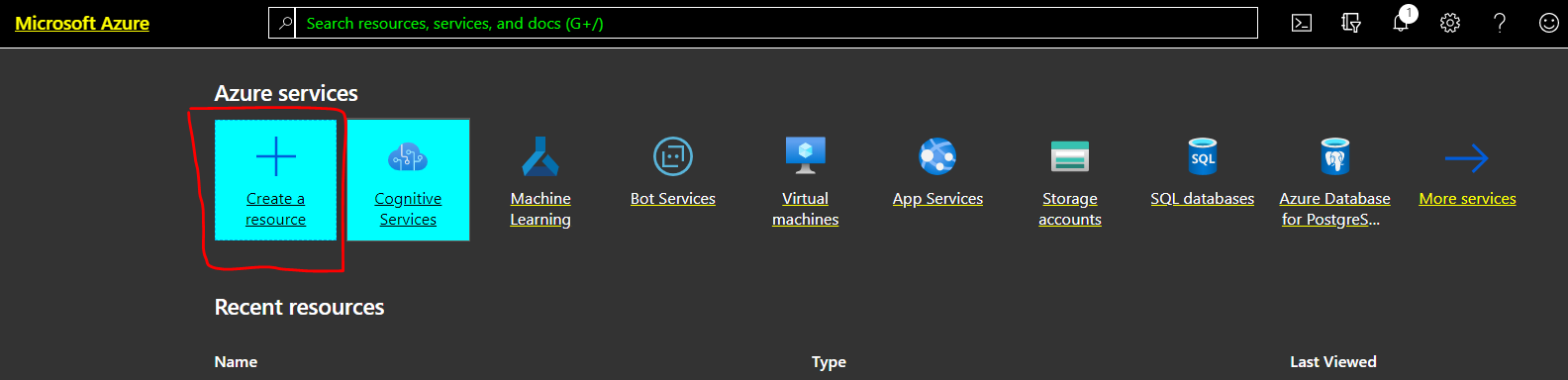
Select "AI + Machine Learning" and "Text Analytics"

Fill the required input and click on "Create new". The input required in Resource group is subscription name in step 1.

If not any errors happen, the new resource is added in Home page as the following :
Click on the resource name, it is where we obtain the subscription key and endpoint request
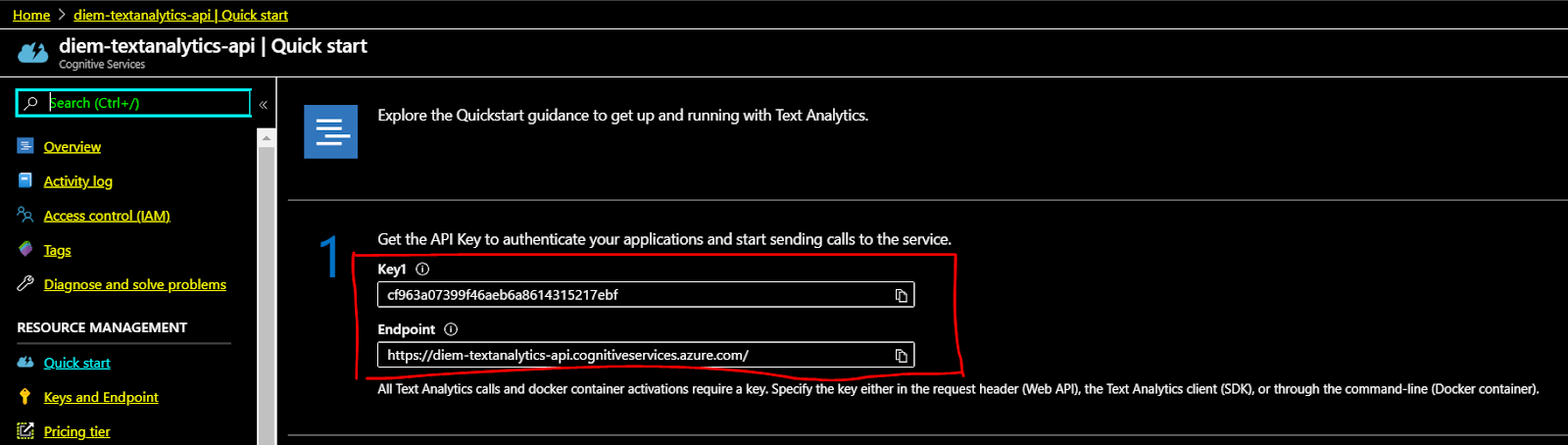
Mission accomplished !!!
3) Request parameters for Sentiment Analysis
Request has 3 main parts: Header, URL and JSON documented-data
Header is dictionary object whose the key is "Ocp-Apim-Subscription-Key" and the value is API key in the previous step.
A complete URL comprises 2 parts: Endpoint in the above image plus the API URI which is indicated particularly to our purpose. At this moment, we use Azure API to detect the sentiment hidden in the text
JSON document is an array of JSON object consisting of key, language and text.


First, the sent request has no errors so that we can continue analyzing the response data. Clearly that score of text 3, text 5 and text 6 got very small which means they are negative because some words like "shiver", "crie", "die" appear in the text. The expected results are not bad at all !!!
5) JSON response from Entities Extraction Request
The only thing we should do is to modify the API request and JSON document in request body and send them to the Azure

The output is very comprehensive and informative. It found 2 entities in text: Statue of Liberty and New York city. The confidence score for the prediction is about greater than 0.8. Also It provides the location of the entities.
6) JSON response from Language Identification request
Language detection is one of sub fields of Natural Language Processing which recognizes the natural languages used in the text. Similar to precedent part, URL and JSON document are changed to be compatible with purpose use.

As we can see, 3 different languages are detected in the texts are English, Vietnamese and French with confidence score is 1.0










